Préambule
Objectifs
Passons maintenant aux descriptions comportementales. Dans ce
type de descriptions, il y a plusieurs
niveaux.
Nous allons ici étudier les principales descriptions
:
- celle au niveau des équations booléennes, appelée aussi
parfois flot de données. Ce type de
représentation modélise les circuits combinatoires,
non pas en instanciant des portes, mais sous forme d'équations
booléennes.
- Pour les circuits séquentiels, il faudra faire appel à un
niveau plus abstrait, appelé RTL.
Les objectifs de ce chapitre sont de comprendre :
- les différences entre affectations continues et affectation
procédurales
- les différences entre les processus, always
et initial,
- les différences entre blocs parallèles et séquentiels
- les différences entre affectations procédurales bloquantes
et non bloquantes
- les structures de contrôle utilisées dans les processus
- les mécanismes de contrôle événementiel des processus
- les différents types de délais dans les affectations
procédurales
Plan du chapitre
Affectations
continues
Les affectations continues permettent d'affecter des valeurs
aux noeuds (wire).
Elles modélisent des circuits combinatoires, sous une forme concise.
Cette forme ne présume rien de la façon dont la fonction sera
implémentée en pratique. Ce n'est qu'une représentation
de la fonction réalisée, qui peut être réaliser
en pratique avec d'autres fonctions logiques que celles écrites (du
moment que la fonction booléenne reste la même).
Les affectations continues modélisant des circuits
combinatoires, ce sont des affectation permanentes.
Une fois qu'un noeud subit une affectation, cette affectation ne peut
plus être modifiée.
Une affectation continue de déclare ainsi, à l'intérieur d'un
module :
assign noeud = .... ;
Une forme concise permet de déclarer un noeud et de lui assigner une
valeur en même temps.
Exemple
:
wire [7:0] bus = a & b;
La cible d'une affectation continue peut être :
- un noeud (wire)
- un bit d'un noeud vecteur (bus) : bus[4]
- une sélection de bits d'un noeud vecteur (bus) : bus[5:2]
- une concaténation de ce qui précède : {a,
bus[7:3], bus[0], bus}
Les affectations continues sont déclarées en dehors de tout
processus
always ou initial. C'est normal : elles sont continues. Si l'expression
à affecter à un signal doit être modifiée au cours du temps, il est
alors nécessaire d'utiliser le type reg et les affectations
procédurales.
Les affectations continues définissent des processus
implicites. Par exemple : assign
s = a + b; définit aussi un processus implicite, exécuté à
chaque changement de a ou
b.
A retenir
:
Les affectations continues
et le type wire seront
utilisées pour modéliser de la logique combinatoire dont l'expression
est simple.
Pour la logique séquentielle, ou combinatoire dont
l'expression est complexe, on utilisera les reg
et les affectations procédurales.
Attention
:
Il est possible d'utiliser
le type reg dans une affectation continue. Cela a une signification
bien particulière, qui dépasse le cadre de ce cours. Mais il ne faut
pas compter sur les simulateurs et synthétiseurs pour détecter
un emploi erroné du type reg dans une affectation continue.
Processus
Verilog est un langage concurrent (parallèle) contrairement au
C qui est par nature un langage séquentiel : les différentes tâches
d'un programme Verilog s'exécutent en parallèle les unes des autres.
Ces tâches sont appelées processus. Nous avons déjà vu des processus,
sans l'avoir dit :
- une instance d'une primitive (un and
par exemple) définit un processus implicite, qui est exécuté à chaque
changement d'une des entrées,
- une affectation continue d'un noeud (assign
s = a + b; ) définit aussi un processus implicite, exécuté
à chaque changement de a
ou b
Les processus peuvent aussi être déclarés explicitement dans
un module. Ils se composent alors d'une en-tête, et d'une suite
d'instructions.
- l'en-tête définit le type de processus (always ou initial)
- alors que les processus d'un module s'éxécutent en
parallèle les uns des autres, les instructions à l'intérieur
d'un processus peuvent s'éxécutent soit de façon séquentielle
ou soit de façon parallèle.
Type des processus
Il existent deux type de processus explicites, ceux qui ne
sont exécutés qu'une seule fois en tout et pour tout, et ceux exécutés
plusieurs fois (généralement
au changement d'état d'une entrée)
- initial
- les processus déclarés par le mot-clef initial ne sont exécutés qu'une
seule fois, au début de la simulation (au temps 0)
L'ordre dans lequel les diférents processus initial
sont exécutés n'est pas spécifié, et dépend du simulateur.
Les processus initial
sont typiquement utilisés pour initialiser les variables.
- always
-
- les processus déclarés par le mot-clef always sont exécutés en
permanence, en commençant au temps 0. Ils doivent alors comporter au
moins un point d'arrêt pour permettre au temps d'avancer (voir le chapitre
sur la simulation).
L'ordre dans lequel les diférents processus always
sont exécutés n'est pas spécifié, et dépend du simulateur. C'est au
concepteur de faire attention à concevoir un code ne dépendant par de
l'ordre d'exécution des processus.
Les processus always sont
utilisés pour modéliser une activité répétée continuement dans un
circuit (un bloc, ...), qui ne s'arrête qu'à la mise hors-tension (off)
du circuit.
Exécution des instructions
Les instructions comportementales dans un processus peuvent
être exécutées de façon parallèle ou séquentielle.
- les instructions comprises dans un bloc begin...end seront exécutées se
façon séquentielle
- les instructions comprises dans un bloc fork...join seront exécutées se
façon parallèle
On notera que les blocs begin...end
et fork...join :
- peuvent être imbriqués
- sont nécessaires après un always,
initial, if then else, case, ... si on veut exécuter plus
d'une seule instruction : les instructions à exécuter doivent alors
être groupées dans un bloc begin...end
ou fork...join
- peuvent comporter des variables locales. Ils doivent alors
être nommés (il faut donner un nom au bloc).
Exemple
L'exemple suivant modélise un générateur d'horloge :
module clock_gen (clock);
output clock;
reg clock;
// initialise la variable clock
initial
clock = 0;
// en permance change l'état de clock tous les 10ns
always
begin
#10;
// met le processus en pause pour 10
unités de temps.
clock = ~clock; // inverse clock
end
endmodule
Exercice
:
On a inversé l'ordre des instructions du bloc begin...end :
module clock_gen (output clock);
reg clock;
// initialise la variable clock
initial
clock = 0;
// en permanence change l'état de clock tous les 10ns
always
begin
clock = ~clock;
#10;
end
endmodule
Réponse : 0
ou 1, tout dépend du
simulateur. Si le processus initial
est exécuté en premier, ce sera 1,
sinon ce sera 0.
Affectations
procédurale
Nous avons vu les affectation continues,
qui affectent en permanence une valeur à un noeud (wire).
Elle sont déclarées en dehors de tout processus (car elles définissent
un processus implicite).
Dans un processus, les affectations ne concernent que les
variables (reg,
integer, ...). On les
appelle affectations procédurales.
Comme vu au chapitre
sur la simulation, il en existe deux types :
- celles utilisées pour la communication entre processus, qui
sont différées à la fin du delta-cycle en cours. On les appelle non
bloquantes.
Elles sont écrites ainsi : a <=
b;
- celles utilisées pour les variables internes à un
processus. Elles sont immédiates, effectuées tout de suite. On les
appelle bloquantes.
Elles sont écrites ainsi : a = b;
Exercice
:
- que va afficher le code suivant ? (pour la réponse, simulez
le )
module test;
reg a, b;
initial
begin
a <= 1;
$display("a = ", a);
end
initial
begin
b = 1;
$display("b = ", b);
end
endmodule
- On veut écrire un processus qui échange les octets de poids
fort et faible d'une variable word
(16 bits).
reg [15:0] word;
always @(posedge clk)
begin
// échange les octets de poids fort et faible de
word
word[15:8] = word[7:0];
word[7:0] = word[15:8];
end
- le code ci-dessus ne fonctionne pas, pourquoi ? Comment le
modifier pour qu'il fonctionne ?
[Afficher
la réponse]
Réponse :
Les affectations étant bloquantes, elles sont exécutées
immédiatement.
word[15:8] est donc
modifié, mais pas word[7:0].
Pour obtenir un code correct, il suffit de remplacer les
affectation immédiates par des affectations différées (non bloquantes).
reg [15:0] word;
always @(posedge clk)
begin
// échange les octets de poids fort et faible de word
word[15:8] <= word[7:0];
word[7:0] <= word[15:8];
end
Affectations
procédurale forcées
Nous avons vu les affectation continues
et les affectations procédurales. Il existe un
troisième type d'affectations, plus rare, qu'on mentionne ici pour être
complets. Ce sont les affectations procédurales forcées. Elles
permettent de préempter une autre affectation depuis un processus,
c'est-à-dire de forcer une variable ou un net à une valeur précise, et
ce même si d'autres affectations surviennent : en d'autres mots, elles
priment sur tout. C'est pour cela qu'on les utilise parfois pour
modéliser des reset dans des testbenchs. Mais attention, elles ne sont
souvent pas synthétisables !
- assign / deassign
- assign permet
de forcer une variable (reg)
à une certaine valeur (qui peut être une expression) même si d'autres
affectation surviennent plus tard.
deassign permet de
retirer ce forçage. La variable garde quand même la même valeur jusqu'à
ce qu'une affectation (forcée ou non) lui en donne une nouvelle.
- force / release
- force fait la
même chose que assign,
mais peut porter sur une reg
ou un wire.
release est équivalent
à deassign. Dans le cas
où force portait sur un wire, le wire
retrouve instantanément sa valeur normale.
Exemple:
module top;
wire [9:0] pixels, black_pixels;
// Produit un premier flux normal de pixels
video_output(pixels);
// Produit un deuxième flux de pixels contenant
seulement des synchros (EAV/SAV)
empty_video(black_pixels);
// Switch au vol entre les deux flux
always @(posedge clk)
begin
if(line==220)
force pixels =
black_pixels + 16;
if(line==21)
release pixels;
end
endmodule
Structures de
contrôle
On retouve en Verilog des structures de contrôle similaires à
celles du C :
- les instructions de test (if,
case)
- les boucles (for,
repeat, while, forever)
ainsi que des structures de contrôle du temps (synchronisation
des processus, mise en veille) :
- attente d'un événement : @
- attente d'un état : wait
- delais : #
Instructions de test
Syntaxe :
- if(condition)
instruction_ou_bloc;
- if(condition)
instruction_ou_bloc; else instruction_ou_bloc;
La condition est
évaluée, si elle est vraie l'instruction est exécutée, sinon celle de
l'éventuel else l'est.
Attention
: une condition est fausse si elle évaluée en 0,
z ou x.
Exemple
:
if(a==0)
begin
// bloc exécuté si a vaut 0
end
else
begin
// bloc exécuté si a ne vaut pas 0
end
if(a)
begin
// bloc exécuté si a est vrai
end
else
begin
// bloc exécuté si a vaut 0, x, ou z
end
Exemple
: les deux blocs suivants ne sont pas équivalents
! Pourquoi ?
if(a == b)
<instruction1>;
else
<instruction2>;
if(a != b)
<instruction2>;
else
<instruction1>;
Une autre forme d'instructions de test : le case , qui diffère de celui du C
par le fait que :
- les break sont implicites,
- il en existe trois formes, différant par le traitement des z et x
:
- case
compare les bits de l'expression et des alternatives bit-à-bits.
Si les tailles ne sont les mêmes, le plus petit est complémenté à
gauche avec des 0.
- casez
compare les bits de l'expression et des alternatives bit-à-bits, mais
seulement les 0, 1 et x.
Les z sont ignorés.
Les positions de bits en z
peuvent aussi être écrites avec des ?.
Si plusieurs alternatives conviennent, la première est exécutée.
Si les tailles ne sont les mêmes, le plus petit est complémenté à
gauche avec des 0.
- casex
compare les bits de l'expression et des alternatives bit-à-bits, mais
seulement les 0 et 1. Les z
et x sont ignorés.
Si plusieurs alternatives conviennent, la première est exécutée.
Si les tailles ne sont les mêmes, le plus petit est complémenté à
gauche avec des 0.
- on ne peut pas grouper les alternatives (un seul choix à la
fois)
Exemples
:
reg [15:0] rega;
reg [9:0] result;
case (rega)
16'd0: result = 10'b0111111111;
16'd1: result = 10'b1011111111;
16'd2: result = 10'b1101111111;
16'd3: result = 10'b1110111111;
16'd4: result = 10'b1111011111;
16'd5: result = 10'b1111101111;
16'd6: result = 10'b1111110111;
16'd7: result = 10'b1111111011;
16'd8: result = 10'b1111111101;
16'd9: result = 10'b1111111110;
default result = 10'bx;
endcase
/****************************/
reg [7:0] ir;
casez (ir) // les z (ou ?) sont ignorés
8'b1???????: <instruction>;
8'b01zzzzzz: <instruction>;
8'b00010???: <instruction>;
8'b000001??: <instruction>;
endcase
/****************************/
reg [7:0] r, mask;
// r = 8'b01100110
mask = 8'bx0x0x0x0;
casex (r ^ mask) // les z (ou ?) sont ignorés
8'b001100xx: <instruction>;
8'b1100xx00: <instruction>;
8'b00xx0011: <instruction>;
8'bxx010100: <instruction>;
endcase
/*****************************************************/
// Cas du selecteur constant
// pour les machines à état one-hot
// ATTENTION, ce style de code est souvent illisible !
reg [2:0] encode;
case (1)
encode[2] : $display("Select Line 2");
encode[1] : $display("Select Line 1");
encode[0] : $display("Select Line 0");
default $display("Error: One of the bits expected ON");
endcase
Remarque importante pour les gens venant du VHDL
parallel_case
Avec les
casez
et
casex, Verilog donne
la possibilité d'avoir des conditions qui se chevauchent (contrairement
au VHDL). Un encodeur de priorité est alors construit. Lorsqu'on
sait
qu'en réalité les conditions ne se chevaucheront jamais, on a la
possibilité d'indiquer au synthétiseur que les conditions sont purement
parallèle et que ce n'est donc pas la peine de synthétiser un encodeur
de priorité. Cela est fait au moyen d'attributs :
(* parallel_case *)
casez(Va)
3'b1??: a0 = 1;
3'b?1?: a1 = 1;
3'b??1: a2 = 1;
endcase
// ou bien
casez(Va) // pragma parallel_case
3'b1??: a0 = 1;
3'b?1?: a1 = 1;
3'b??1: a2 = 1;
endcase
La logique synthétisée est alors plus rapide car plus petite. Mais ça a
deux inconvénients majeurs :
- les comportements en simulation et post-synthèse sont alors
différents ! La preuve d'équivalence est impossible...
- beaucoup de gens ajoutent cet attribut automatiquement sans
avoir conscience qu'il faut être sûr qu'on n'aura
jamais
de chevauchement. En cas de chevauchement, le design a de
bonnes chances de partir en tape-out avec des erreurs majeures alors
que la simulation se passe correctement !
Recommandation
: coder les encodeurs de priorité à base de if / else, et oublier
l'attribut parallel_case !
full_case
Si on ne spécifie pas tous les cas possible du case, des latchs sont
syntétisés. Un autre attribut existe :
(*
full_case *) indiquant au synthétiseur que les cas non
spécifiés sont don't care, et qu'il peut générer ce qu'il veut dans ces
cas là.
Mêmes problèmes que plus haut :
- les comportements en simulation et post-synthèse sont alors
différents ! La preuve d'équivalence est impossible...
- contrairement à une croyance répandue, cela n'empêche pas
les latchs !
Recommandations
:
- oublier cet attribut
- toujours prévoir un cas default
Pour plus de précisions, on se rapportera à
l'excellent
papier de Don Mills et Sutherland sur le sujet !
Les boucles
- forever
(boucle infinie)
- repeat (un
nombre fixé d'itérations)
- while (tant
qu'une condition est vraie)
- for (comme
en langage C)
Attention aux boucles forever,
il faut une condition d'arrêt dans l'intérieur
de la boucle, sinon le temps n'avance pas !
Les mêmes remarques sur l'évaluation des conditions que pour le if s'appliquent
! (une condition est fause si elle s'évalue en 0,
x ou z,
elle est vraie sinon)
Exemple
:
begin: count1s
reg [7:0] tempreg;
tempreg = rega;
for(count = 0; tempreg; tempreg = tempreg >> 1)
count = count + tempreg[0];
end
Exercice
:
- que fait le bloc ci-dessus ?
Structures de contrôle
du temps, synchronisation des processus
Il en existe trois, qui servent aussi de point d'arrêt :
- attente d'un événement : @
- attente d'un état : wait
- delais : #
Contrôle événementiel
Le symbole @ est
utilisé pour spécifier un contrôle événementiel. Il bloque un processus
(mise en veille), jusqu'à ce qu'un événement (changement d'état) sur le
signal spécifié se produise.
On peut lui adjoindre le modificateur posedge
ou negedge pour
filtrer les transitions montantes ou descendantes.
La table suivante définit ce que sont les transistions
montantes et descendantes :
| |
vers 0 |
vers 1 |
vers x |
vers z |
| de 0 |
- |
montante
|
montante |
montante |
| de 1 |
descendante |
- |
descendante |
descendante |
| de x |
descendante |
montante |
- |
- |
| de z |
descendante |
montante |
- |
- |
Si l'opérande de @
est un vecteur, c'est le bit de poids faible qui donne le type de
transition.
On peut grouper plusieurs événements avec le mot-clef or ou avec une virgule (ou une
combinaison des deux).
Exemple
:
@r rega = regb; // l'affectation ne
s'effectue qu'après un changement de n'importe quel bit de r
@(posedge clock) rega = regb; // l'affectation ne s'effectue qu'après
un front montant de clock
@(negedge clock) rega = regb; // l'affectation ne s'effectue qu'après
un front descendant de clock
@(posedge clock or negedge reset) // l'affectation suivante ne
s'effectue qu'après un front
rega = regb;
//
montant de clock ou un front descendant de reset
@(a, b or c) // l'affectation suivante ne
s'effectue qu'après un
événement
rega = regb; // sur a, b, ou c
Contrôle sur état
L'instruction wait
prend en argument une condition.
Elle teste la condition et, si elle est fausse, bloque l'exécution du
processus jusqu'à ce qu'elle soit vraie.
Si la condition est vraie lors du test, l'exécution n'est pas bloquée.
Exemple
:
wait (enable) // l'affectation
attend que enable vaille 1 pour s'exécuter
rega = regb;
// Attention, les deux exemples suivant ne SONT PAS equivalents
(pourquoi ???)
begin
@(posedge clk) q1 <= d;
wait(clk) q2 <= q1;
end
begin
@(posedge clk) q1 <= d;
@(posedge clk) q2 <= q1;
end
Délais
On peut spécifier explicitement des pauses dans l'exécution
d'un processus, en unité de temps, au moyen du symbole #.
Le temps de pause peut être spécifié à l'aide d'une constante ou d'une
expression.
Si le temps de pause n'est pas entier, il est arrondi selon la
précision temporelle du simulateur.
La précision temporelle
est spécifiée au moyen de la directive `timescale
(le
premier caractère est un guillemet simple inversé, obtenu sur un
clavier de PC
par les touches AltGr et 7...). Cette directive spécifie l'unité de
temps du
simulateur et sa précision. L'unité de temps et la précision utilisées
par défaut,
si aucune directive `timescale
n'est utilisée, dépendent du simulateur (généralement 1ns / 1ps).
Exemple
:
`timescale 1 ns / 1 ps // le temps
sera spécifié en multiples de 1ns, avec une précision de 1ps
...
begin
a = 1;
#10; // mise en pause du processus pour 10ns
a = 0;
end
`timescale 10 ns / 100 ps // le temps sera spécifié en multiples de
10ns, avec une précision de 100ps
real half_period;
reg clock;
initial
begin
clock = 0;
half_period = 5.99999;
end
always
begin
#half_period; // mise en veille du processus
pendant 60 ns.
clock <= ~clock;
end
Exercice
:
- que modélise le code du bas dans l'exemple ci-dessus ?
Les délais sont généralement utilisés dans les blocs initial pour générer des stimuli
de test.
Exemple
:
reg [7:0] a, b;
reg cin;
...
initial
begin
a = 0; b = 0; cin = 0;
#10;
a = 1 ; b = 2; cin = 0;
#10;
a = 221; b = 134; cin = 1;
#10;
a = 0; b = 255; cin = 1;
end
Processus et
listes de sensibilité
Liste de sensibilité
Un processus peut être synchronisé explicitement, à l'aide
d'une des instructions de contrôle temporel ci-dessus, ou de façon
implicite à l'aide d'une liste de sensibilité.
Cette liste de sensibilité est spécifiée à l'aide du symbole @ juste après le mot-clef always. Cette liste peut comporter
un ou plusieurs signaux, séparés alors par le mot-clef or ou une virgule.
Elle permet de n'exécuter le processus que lors d'un événement sur l'un
des signaux dans la liste.
Exemple
: une bascule D simple est un dispositif qui échantillonne une entrée
sur le front montant d'une horloge. Une description Verilog d'une
bascule D serait donc :
module DFF(clock, d, q);
input clock;
input d;
output q;
reg q;
always @(posedge clock)
q <= d;
endmodule
Exercice
:
- Donnez une description d'une bascule D possédant un reset asynchrone
(qui remet la bascule à zéro s'il passe à l'état bas)
- Donnez une description d'une bascule D possédant un reset synchrone
(qui remet la bascule à zéro s'il est à l'état bas lors
d'un front montant de l'horloge)
[Afficher
la réponse]
Réponse :
- un reset asynchrone agit
indépendement de l'horloge. Il doit donc faire partie de la liste de
sensibilité de la bascule D.
module DFF(clock, reset, d, q);
input clock;
input reset;
input d;
output q;
reg q;
always @(posedge clock or negedge reset)
if(!reset)
q <= 0;
else
q <= d;
endmodule
- un reset synchrone ne doit être pris
en compte qu'au front montant de l'horloge. L'horloge est donc le seul
signal de la liste de sensibilité.
Le code est le même que celui du module ci-dessus, à la liste de
sensibilité près.
module DFF(clock, reset, d, q);
input clock;
input reset;
input d;
output q;
reg q;
always @(posedge clock)
if(!reset)
q <= 0;
else
q <= d;
endmodule
Logique séquentielle et logique combinatoire
Nous avons vu que les affectations continues (assign et wire)
permettent de modéliser de la logique combinatoire seulement.
Nous allong voir qu'un reg,
en dépit de son nom rappelant les registres, peut
servir à modéliser aussi bien de la logique séquentielle que de la
logique combinatoire.
Exemple
:
reg a;
...
always @(b, c)
a <= b & c;
L'affectation a <= b
& c; est exécutée dès que b
ou c change d'état. En
d'autres termes, a ne
dépend que de l'état actuel de b et c,
et pas de leur passé. Ceci est la définition de
la logique combinatoire.
Ce processus modélise donc une porte ET : logique combinatoire,
même si a est un reg !
Exemple
:
reg a;
...
always @(b, c)
if(b)
a <= c;
else
a <= 0;
La valeur de a
dépend de b et c.
Comme b et c figurent tous les deux dans sa
liste de sensibilité, le processus est exécuté à chaque changement
d'état de b ou de c.
De plus, à chaque exécution du processus, une valeur est affectée à a :
- soit la valeur actuelle de c
- soit 0
a ne dépend donc
que de l'état actuel de b
et c, et pas
de leur passé. En d'autres termes, la fonction réalisée est encore une
fonction combinatoire.
Plus précisément la fonction réalisée est a
= b & c (rappel : une porte ET est aussi une mise
à 0).
Exemple
:
reg a;
...
always @(b, c)
if(b)
a <= c;
La valeur de a
dépend de b et c.
Comme b et c figurent tous les deux dans sa
liste de sensibilité, le processus est exécuté à chaque changement
d'état de b ou de c.
Mais dans le cas où b
vaut 0, a n'est
pas affecté et garde son
ancienne valeur.
La fonction réalisée est donc une fonction séquentielle.
Plus précisément, la fonction réalisée est un latch.
Dans
ce processus-ci, un des chemins de contrôle (le if
) n'affecte pas de valeur à a.
C'est de là que
vient la séquentialité du processus.
Un processus est combinatoire si :
- les sorties reçoivent une valeur à chaque à chaque
modification des variables dont elle dépendent.
En d'autre termes, la liste de sensibilité du processus contient toutes
les variables dont dépendent les sorties.
- les sorties sont affectées quel que soit le chemin de
contrôle dans le processus.
Il est séquentiel sinon.
Un des pièges classiques des HDL est l'inférence accidentelle
de latch ou
bascule D alors qu'on voulait écrire un processus combinatoire.
- Pour éviter les listes de sensibilité incomplètes,
Verilog définit les listes de sensibilité implicites, @* qui spécifient que le processus
sera sensible à toutes les variables utilisées.
- Pour éviter les chemins de contrôle incomplets,
il suffit d'initialiser les sorties à une valeur par défaut au début du
processus.
Exemples
:
always @(*) // équivalent à @(a or b
or c or d or f)
y = (a & b) | (c & d) | myfunction(f);
// Le code suivant modélise la tabel d'évolution d'une machine à états,
// souvent utilisé pour spécifier un encodage one-hot,
// MAIS C'EST UN STYLE DE CODAGE DEPLORABLE !!!
always @* // équivalent à @(state or go or ws)
begin
next = 4’b0; // next est initialisé à 0 par
défaut.
// Il reçoit
donc une valeur quel que soit le chemin de contrôle choisi
(case...)
case (1’b1)
state[IDLE]:
if (go)
next[READ] =
1’b1;
else
next[IDLE] =
1’b1;
state[READ]: next[DLY ] = 1’b1;
state[DLY ]:
if (!ws)
next[DONE] =
1’b1;
else
next[READ] =
1’b1;
state[DONE]: next[IDLE] = 1’b1;
endcase
end
always @* // équivalent à @(a or en)
begin
y = 8’hff;
y[a] = !en;
end
Exercice
:
- que fait le dernier exemple de code ?
Affectations et délais
Verilog permet de spécifier des délais dans les affectations.
Selon le type d'affectation (bloquante, non bloquante) et l'endroit où
le délai est spécifié, le comportement modélisé ne sera pas le même. Il
est nécessaire de bien comprendre quel délai modélise quoi, c'est
l'objectif de cette section.
Il existe trois type d'affectations avec délai :
- délai simple : #10 x = y;
- intra-affectation : x =
#10 y;
- délai nul : #0 x = y;
Délai simple
Cette forme de délai est
spécifié à gauche de l'affectation.
Un délai simple retarde le moment d'exécution d'une affectation toute
entière.
- Affectation bloquante : #10
x = y;
- Le processus est mis en veille pendant 10 unités de temps.
Puis x est affecté de
façon immédiate avec ce que vaut y
au temps 10.
- Affectation non bloquante : #10
x <= y;
- Le processus est mis en veille pendant 10 unités de temps.
Puis x est affecté de
façon différée avec ce que vaut y
au temps 10.
En d'autres termes, une
affectation avec délai simple : #10
<affectation> est équivalente à ceci :
#10;
<affectation>;
Délai intra-affectation
Cette forme de délai est
spécifié au mileu de l'affectation (après le signe d'affectation).
Dans ce type de délai, la partie de droite est évaluée instantanément
et mise en mémoire. Puis l'affectation est effectuée au bout du délai
spécifié
(en respectant le fait qu'elle soit bloquant on non bloquante).
- Affectation bloquante : x
= #10 y;
- Au temps 0, la valeur de y
est mémorisée.
Puis le processus est mis en veille pendant 10 unités de temps.
Puis x est affecté avec
la valeur mémorisée.
- Affectation non bloquante : x
<= #10 y;
- Au temps 0, la valeur de y
est mémorisée.
Puis le processus continue de façon normale (sans faire l'affectation).
Au temps 10, l'affectation est effectuée de façon différée (x prend la valeur mémorisée).
Délai nul
Des affectations dans
différents processus peuvent être effectuée au même temps (physique).
L'ordre dans lequel elles seront exécutées est alors non déterministe.
Pour éviter cette situation, les délais nuls peuvent être utilisés :
ils assurent qu'une affectation sera effectuée en dernier, après toutes
les autres.
Exemple :
initial
x = 0;
initial
#0 y = x; // assure que cette affectation sera effectuée
APRES celle du
haut
Bien sûr, si plusieurs
affectations ont un délai nul, l'ordre d'exécution entre
elles est non déterminé.
De toutes façons, un code
ayant besoin de ce genre d'artifice est souvent un code mal écrit.
Il vaut mieux écrire son code proprement, en évitant par
construction le non déterminisme.
Modélisations
Dans le monde réel, il
existe deux types de délais :
- Délai de transport
- C'est le temps de propagation d'un
système.
Tous les changements des entrées sont propagés, avec ce délai.
- Delai inertiel
- Il modélise un temps de transition
fini.
Des variations d'une entrée durant moins que ce délai sont ignorées
(filtrage des parasites).
Exercice
:
- soit le code suivant, modélisant un buffer avec différents
types de délais, ainsi que le chronogramme de son entrée.
Tracez les chronogrammes des sorties.
Conclusion ?
always@(in)
o1 = in;
always@(in)
o2 <= in;
always@(in)
#5 o3 = in;
always@(in)
#5 o4 <= in;
always@(in)
o5 = #5 in;
always@(in)
o6 <= #5 in;

Entrée du
buffer (in)
Réponse :
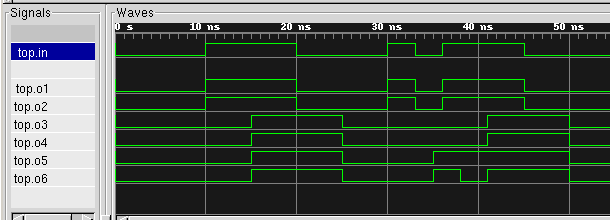
- o6 modélise un
délai de transport
- o3 et o4 modélisent un délai inertiel
Pour plus de détails, on pourra se reporter à ces pages-ci :
Les délais peuvent aussi être utilisés avec le sign @. L'attente d'un délai fixe est
alors remplacée par une attente d'un événement.
Cela permet d'écrire ce genre de choses :
always @(IN)
OUT <= repeat (8) @(posedge clk) IN;
Exercice
:
Réponse : un registre à décalage
à huit étages.
Délais et Verilog structurel
Les délais peuvent apparaitre dans une description
structurelle,
lors de l'instanciation d'un module ou lors d'une affectation continue (assign).
Ces délais spécifient un temps de propagation. Ils peuvent
être
différents selon le type de transition, et avoir une valeur minimum,
maximum et typique.
Dans leur forme simple, ils sont déclarés ainsi :
and #10 and1 (out, i1, i2); // une
porte and ayant un temps de propagation de 10 unités de temps
assign #20 out = i1 & i2; // une fonction (AND) ayant un temps
de propagation de 20 unités de temps
Verilog dispose aussi de moyens de spécifier des délais encore
plus
évolués (de port à port, distribués, localisés, dépendant des
transitions, des conditions de simulation, ...), mais cela sort du
cadre de ce cours...
Paramètres et
généricité
Paramètres
Comme nous l'avons vu en introduction, les modules peuvent
inclure des paramètres permettant d'écrire des modules génériques.
Les paramètres doivent être définis dans le module paramétré
par le mot-clef parameter,
et y recevoir une valeur par défaut.
La valeur par défaut d'un paramètre d'un module peut être
modifiée :
- soit au moment de l'instanciation de ce module, au moyen du
signe #. Les valeurs des
paramètres sont alors passées soit par position, soit par nom.
- soit avant ou après l'instanciation de ce module, au moyen
du mot-clef defparam. Les
valeurs des paramètres sont alors passées par nom.
Exemple
:
module addn(A, B, S);
parameter taille = 8, id = 0;
input [taille-1:0] A, B;
output [taille-1:0] S;
assign S = A + B;
initial
$display("Hello,je suis l'additionneur %d, de taille %d", id, taille);
endmodule
// Passage de paramètre au moment de l'instanciation
module sum;
wire [15:0] A, B, C, D, S;
wire [15:0] TMP1, TMP2;
addn add1(A, B, TMP1);
addn #(16, 1) add2(C, D, TMP2);
addn #(.id(2), .taille(16)) add3(TMP1, TMP2, S);
endmodule
// Passage explicite de paramètres
module sum2;
wire [15:0] A, B, C, D, S;
wire [15:0] TMP1, TMP2;
defparam add1.taille = 16, add2.taille = 16, add3.taille = 16;
defparam add2.id = 1, add3.id = 3;
addn add1(A, B, TMP1);
addn add2(C, D, TMP2);
addn add3(TMP1, TMP2, S);
endmodule
Généricité
Les paramètres ne sont parfois pas suffisant pour écrire un
code générique : on peut aussi vouloir instancier
un nombre variable de portes (en fonction d'un
paramètre, par exemple), voire même différentes
portes... Ceci est fait au moyen des mots-clef generate...endgenerate,
genvar et localparam.
- genvar est un
type de variable qui peut être assigné et modifié à la compilation.
Il joue le rôle de variable dans les instanciations conditionnelles de
matériel.
- localparam est
un type de paramètre qui ne peut pas être surchargé depuis l'extérieur
d'un module (un paramètre local, quoi !)
- generate...endgenerate
délimite les blocs où un nombre arbitraire de matériel sera généré.
Exemple
: on veut décrire un multiplieur générique, tel que
- s'il doit manipuler des nombres de largeur inférieure à 8
bits, il doit avoir une achitecture Carry Lookhead (CLA)
- sinon il doit avoir une architecture de type arbre de
Wallace.
module multiplier (a, b, product);
parameter a_width = 8, b_width = 8;
localparam product_width = a_width + b_width;
input [a_width-1:0] a;
input [b_width-1:0] b;
output [product_width-1:0] product;
generate
if((a_width < 8) || (b_width < 8))
begin
CLA_multiplier #(a_width, b_width) u1 (a, b, product);
initial
$display("On a instancié un multiplieur CLA");
end
else
begin
WALLACE_multiplier #(a_width, b_width) u1 (a, b, product);
initial
$display("On a instancié un multiplieur de Wallace");
end
endgenerate
endmodule // multiplier
Exemple
: l'exemple classique de l'additionneur n bits... On utilise ici des
boucles for pour
instancier à la main les différentes primitives ainsi que les noeuds
les connectant entre elles.
module Nbit_adder (co, sum, a, b,
ci);
parameter SIZE = 4;
output [SIZE-1:0] sum;
output co;
input [SIZE-1:0] a, b;
input ci;
wire [SIZE:0] c;
assign c[0] = ci;
assign co = c[SIZE];
genvar i;
generate
for(i=0; i<SIZE; i=i+1)
begin:addbit
wire n1,n2,n3; //internal nets
xor g1 ( n1, a[i], b[i]);
xor g2 (sum[i],n1, c[i]);
and g3 ( n2, a[i], b[i]);
and g4 ( n3, n1, c[i]);
or g5 (c[i+1],n2, n3);
end
endgenerate
endmodule
Exemple
: tiré de la norme Verilog 2001.
parameter SIZE = 2;
genvar i, j, k, m;
generate
for (i=0; i<SIZE; i=i+1) begin:B1 // scope B1[i]
M1 N1(); // instantiates B1[i].N1
for (j=0; j<SIZE; j=j+1) begin:B2 // scope B1[i].B2[j]
M2 N2(); // instantiates B1[i].B2[j].N2
for (k=0; k<SIZE; k=k+1) begin:B3 // scope B1[i].B2[j].B3[k]
M3 N3(); // instantiates B1[i].B2[j].B3[k].N3
end
end
if (i>0) begin:B4 // scope B1[i].B4
for (m=0; m<SIZE; m=m+1) begin:B5 // scope B1[i].B4.B5[m]
M4 N4(); // instantiates B1[i].B4.B5[m].N4
end
end
end
endgenerate
// Some examples of hierarchical names for the module instances:
// B1[0].N1 B1[1].N1
// B1[0].B2[0].N2 B1[0].B2[1].N2
// B1[0].B2[0].B3[0].N3 B1[0].B2[0].B3[1].N3
// B1[0].B2[1].B3[0].N3
// B1[1].B4.B5[0].N4 B1[1].B4.B5[1].N4
Pour aller plus loin
Maintenant que vous êtes un peu familliers avec la génération de blocs, nous vous conseillons de lire attentivement la norme Verilog 2001 section 12.4 (pages 181 à 191) , qui contient beaucoup plus d'exemples, dont certains bien complexes...
Tâches et fonctions
Pour faciliter l'écriture de codes complexes, Verilog dispose
de
tâches et de fonctions, qui jouent un peu le rôle des sous-programmes
(procedures et fonctions) des langages de programmation habituels.
Les différences entre tâches et fonctions sont les suivantes :
- Une tâche peut contenir des instructions de
synchronisation. Pas les fonctions, qui doivent s'exécuter en temps
nul (toutes les assignations dans une fonction sont donc bloquantes).
- Une fonction doit avoir au moins une entrée et renvoie une
seule valeur.
Une tâche peut ne pas avoir d'entrée, et ne renvoie pas de valeur, mais
dispose à la place de sorties (output)
et d'entrées-sorties (inout).
Les fonctions et les tâches :
- n'ont pas de noeuds (wire),
- n'ont pas blocs always
ou initial
- sont déclarées dans un module
- leurs variables locales (reg,
integer, ...) sont statiques,
sauf pour les fonctions déclarées automatic
(leur variables sont alors allouées dynamiquement, autorisant les
fonctions récursives). Dans le cas de tâches automatiques, les variables sont désallouées
à la sortie de la tâche. Il faut donc prendre soin de ne pas les
utiliser dans des constructions qui pourraient y faire référence après
sortie de la tâche (par exemple, dans des assignations non bloquantes)
!!
Les fonctions sont donc utilisées pour les fonctions purement
combinatoires (et sans délais).
Les tâches sont utilisées comme des sous-programmes.
Exemples
:
task MinMax;
input [7:0] a, b;
output [7:0] Min, Max;
begin
#3 Min = (a < b) ? a : b;
#3 Max = (a < b) ? b : a;
end
endtask
...
MinMax(x, y, z, t);
function [7:0] Min;
input [7:0] a, b;
begin
Min = (a < b) ? a : b;
end
endfunction
...
z = Min(x, y);
module sequence;
reg clock;
initial
init_sequence; // invoque la tâche init_sequence
always
sequence; // invoque la tâche sequence
task init_sequence; // cette tache opere directement sur le reg clock
du module
begin
clock = 1'b0;
end
endtask
task sequence; // cette tache opere directement sur le reg clock du
module
begin
#12 clock <= 1'b0;
#5 clock <= 1'b1;
#3 clock <= 1'b0;
#10 clock <= 1'b1;
end
endtask
endmodule
function automatic [63:0] factorial;
// automatic : chaque appel de la fonction dispose de ses propres
variables (n)
input [31:0] n;
if (n == 1)
factorial = 1;
else
factorial = n * factorial(n-1);
endfunction
Automatic ou non ???
On
peut se demander quel est l'intérêt (hormis pour les fonctions
récursives) des fonctions automatiques... Au point de vue "consommation
mémoire", qu'en pensez-vous ?
Fonctions constantes
Il
est possible d'utiliser certaines fonctions pour le calcul de
paramètres. Ces fonctions sont appelées constantes car leurs paramètres
doivent être constants. En d'autres termes, ces fonctions doivent
pouvoir être exécutées
à la compilation (rigoureusement : à
l'élaboration). Typiquement, on s'en servirait pour calculer le
logarithme de la profondeur d'une RAM pour connaitre la largeur de son
bus d'adresse. Des exercices vous seront proposés plus tard dans le
cours vous permettant de manipuler ce genre de fonctions.
En
résumé
Ce chapitre vous a présenté les façons de décrire la
fonctionnalité
des processus, c'est-à-dire leur description comportementale.
Les descriptions comportementales ne s'opposent pas aux
description
structurelles. Elle se complètent : on adopte une description
structurelle pour séparer un bloc en sous-systèmes simples, qui eux
seront décrits comportementalement.
wire / reg ?
- pour de la logique combinatoire ayant une expression simple
: wire et affectations
continues
- pour le la logique séquentielle, ou combinatoire ayant une
expression complexe : reg,
processus et affectations procédurales.
Les processus s'exécutent en parallèle les uns des autres,
mais leur
déroulement interne est séquentiel. Ils peuvent utiliser la plupart des
structures de contrôle du C.
Les processus always s'exécutent en boucle, et nécessitent
donc un
point d'arrêt pour que le temps puisse s'écouler. Il en existe trois :
- wait(...)
- @(...) (utilisé aussi dans les listes de sensibilité)
- #...
L'objectif du prochain chapitre est de :
- faire la différence
entre les constructions synthétisables et celles spécifiques à la
simulation,
- apprendre les mécanismes de contrôle des simulations.
.


